Introduction to Principal Component Analysis
Contributers: Linghao Dong, Josh Beck, Jose Figueroa, Yuvraj Chopra
Sections:
Origin
This notebook was adapted from amueller’s notebook, “1 - PCA”. Here is the link to his repository https://github.com/amueller/tutorial_ml_gkbionics.git .
This notebook provides examples for eigenvalues and eigenvectors in LaTeX and python.
Learning Objective
- How the Principal Componenet Analysis (PCA) works.
- How PCA can be used to do dimensionality reduction.
- Understand how PCA deals with the covariance matrix by applying eigenvectors.
PCA
PCA can always be used to simplify the data with high dimensions (larger than 2) into 2-dimensional data by eliminating the least influntial features on the data. However, we should know the elimination of data makes the independent variable less interpretable. Before we start to deal with the PCA, we need to first learn how PCA utilizes eigenvectors to gain a diagonalization covariance matrix.
Eigenvectors
Eigenvectors and eigenvalues are the main tools used by PCA to obtain a diagnolization covariance matrix. The eigenvector is a vector whos direction will not be affected by the linear transformation, hence eigenvectors represents the direction of largest variance of data while the eigenvalue decides the magnitude of this variance in those directions.
Here we using a simple (2x2) matrix $A$ to explain it. \(A = \begin{bmatrix} 1 & 4 \\ 3 & 2 \end{bmatrix}\)
```# importing class import sympy as sp import numpy as np import numpy.linalg as lg A = np.matrix([[1,4],[3,2]])
</div>
</div>
In general, the eigenvector $v$ of a matrix $A$ is the vector where the following holds:
$$
Av = \lambda v
$$
for which $\lambda$ stands for the eigenvalue such that linear transformation on $v$ can be defined by $\lambda$
Also, we can solve the equation by:
$$
Av - \lambda v = 0 \\
v(A-\lambda I) = 0
$$
While $I$ is the identity matrix of A
$$
I = A^TA = AA^T
$$
In this case, if $v$ is none-zero vector than $Det(A - \lambda I) = 0$, since it cannot be invertible, and we can solve $v$ for $A$ depends on this relationship.
$$
I = \begin{bmatrix}
1 & 0 \\
0 & 1
\end{bmatrix} \\
$$
<div markdown="1" class="cell code_cell">
<div class="input_area" markdown="1">
```def solveLambda(A = A,Lambda = sp.symbols("Lambda", real = True) ):
I = A*A.I
I = np.around(I, decimals =0)
return (A - Lambda*I)
Lambda = sp.symbols("Lambda", real = True)
B = solveLambda(A = A, Lambda = Lambda)
B
To solve the $\lambda$ we can use the function solve in sympy or calculating.
```function = Lambda*2 - 3Lambda - 10 answer = sp.solve(function, Lambda) answer
</div>
<div class="output_wrapper" markdown="1">
<div class="output_subarea" markdown="1">
{:.output_data_text}
[-2, 5]
</div>
</div>
</div>
In this case, $\lambda_1 = -2$ and $\lambda_2 = 5$, and we can figure out the eigenvectors in two cases.
For $\lambda_1 = -2$
<div markdown="1" class="cell code_cell">
<div class="input_area" markdown="1">
```identity = np.identity(len(A))
eigenvectors_1 = A - answer[0]*identity
eigenvectors_1
Based on the matrix we can infer the eigenvector can be \(v_1 = \begin{bmatrix} -4 \\ 3\end{bmatrix}\)
For $\lambda = 5$
```eigenvectors_2 = A - answer[1]*identity eigenvectors_2
</div>
<div class="output_wrapper" markdown="1">
<div class="output_subarea" markdown="1">
{:.output_data_text}
matrix([[-4.00000000000000, 4], [3, -3.00000000000000]], dtype=object)
</div>
</div>
</div>
Based on the matrix we can infer the eigenvector can be
$$
v_2 = \begin{bmatrix}
1\\
1\end{bmatrix}
$$
All in all, the covariance matrix $A'$ now can be:
$$
A' = v * A \\
$$
Such that we can obtain the matrix $V$
$$
V = \begin{bmatrix}
-4 & 1 \\
3 & 1
\end{bmatrix}
$$
where $A' = V^{-1} A V$ for the diagnalization:
<div markdown="1" class="cell code_cell">
<div class="input_area" markdown="1">
```V = np.matrix([[-4,1],[3,1]])
diagnalization = V.I * A * V
diagnalization
Hence, the diagonalization covariance matrix is
\(\begin{bmatrix}
-2 & 0\\
0 & 5
\end{bmatrix}\)
Luckily, PCA can do all of this by applyng the function pca.fit_transform(x) and np.cov()
Generating Data
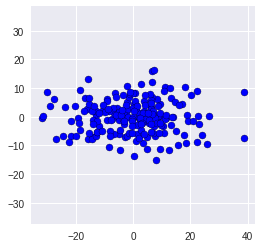
To talking about PCA, we first create 200 random two-dimensional data points and have a look at the raw data.
```import numpy as np import matplotlib.pyplot as plt Cov = np.array([[2.9, -2.2], [-2.2, 6.5]]) X = np.random.multivariate_normal([1,2], Cov, size=200) X
</div>
<div class="output_wrapper" markdown="1">
<div class="output_subarea" markdown="1">
{:.output_data_text}
array([[-0.3314, 3.89 ], [-0.7628, 3.1064], [ 1.6646, 0.7326], [-0.0324, 3.3294], [ 1.4957, 1.7005], [ 2.4818, -4.1281], [-1.0768, 0.5441], [-0.0016, -0.197 ], [ 2.1528, -3.6236], [ 0.7061, 5.6325], [ 1.9122, -3.3293], [ 0.7292, 2.2281], [-2.1433, 1.2667], [ 0.8705, 7.423 ], [-0.0862, 3.7529], [ 1.2707, -2.7226], [ 0.0611, 3.5154], [-1.7579, 10.868 ], [ 1.0198, 2.4983], [-0.0665, 2.5196], [-0.558 , 4.4565], [ 2.1584, 1.4487], [-0.3084, 1.2216], [ 1.9434, 0.8833], [-0.0335, 0.0624], [ 1.199 , -2.2869], [ 1.6465, 1.6136], [ 1.374 , -1.2927], [ 2.1607, 2.5391], [ 0.1091, 7.8452], [ 1.1176, -2.4849], [ 3.2651, -0.5992], [ 4.03 , 0.0084], [ 2.5643, 0.2302], [ 0.4196, -0.2854], [-0.6474, -1.4366], [ 0.6727, 2.1102], [ 2.2817, 1.1636], [-0.3117, 0.8201], [ 2.4958, -0.4984], [ 2.289 , 0.6661], [ 0.2565, 2.3338], [-2.5811, 2.7491], [ 0.2393, 3.3853], [ 1.2671, 0.6598], [ 1.1784, -1.9555], [ 0.7458, 4.5397], [ 1.7347, -0.0982], [ 2.3371, 0.3336], [-1.2219, 2.6902], [ 5.8417, -2.0452], [ 2.4971, -4.8371], [ 0.8998, 3.7154], [ 3.1265, 1.4012], [ 0.5932, -0.6629], [ 4.7175, 0.306 ], [-0.6361, 2.9971], [ 1.5415, 3.6623], [-1.8985, 6.8546], [ 0.36 , 3.0732], [ 0.3536, 1.9734], [ 1.2103, 0.9567], [ 1.1925, 4.6863], [ 0.2706, 3.2078], [ 1.6517, 6.0517], [-0.0253, 2.4021], [ 1.7716, 1.2569], [ 2.74 , -0.2166], [-0.4161, 2.5067], [ 1.3702, 2.6354], [-1.6332, 0.3802], [-0.9584, 5.4841], [ 4.2051, -1.9136], [ 1.7001, -1.057 ], [-2.1647, 3.797 ], [ 0.7634, 3.5773], [ 3.1714, 2.3534], [ 2.893 , 2.1926], [ 1.6868, 2.0728], [ 1.1536, 1.4466], [ 2.3477, 2.9826], [ 0.0636, 3.1583], [ 1.4827, 4.5008], [-3.0736, 4.1688], [ 2.9109, -0.4089], [-0.1036, 5.9447], [-1.0138, 3.7213], [ 0.512 , 2.0402], [ 0.9409, 1.8335], [-0.3748, 2.9108], [ 2.5172, 3.249 ], [ 1.6167, -2.2142], [ 0.9427, 2.962 ], [ 0.1689, 3.8406], [ 5.1565, -2.0153], [ 1.6778, 0.2878], [ 2.3773, 3.6426], [ 3.1883, 6.3567], [ 3.2663, -0.9719], [-0.8649, 1.3055], [ 2.9723, 1.3092], [-0.3873, 3.8015], [-0.6916, 0.2784], [ 1.5806, 2.8773], [-2.6898, 0.2236], [ 1.7335, 2.7428], [-2.8561, 4.9929], [ 0.5896, 3.5652], [ 1.3417, 4.2343], [-1.5769, 3.6546], [-0.2316, 4.0993], [ 2.0261, 2.2127], [ 0.6812, 4.2448], [ 2.5264, -0.1094], [-1.1219, 1.822 ], [ 1.7628, 4.6134], [ 1.4077, -1.5837], [-2.0643, 5.6098], [-1.5796, -0.9632], [ 0.8479, 1.6023], [ 0.5994, 2.7838], [ 1.748 , 0.8479], [ 0.7111, 3.0203], [ 3.1584, 3.6146], [ 1.6388, 0.1935], [ 1.4178, 5.6603], [ 1.3809, -1.65 ], [-2.5293, 1.8252], [ 0.8411, 2.7598], [ 4.4251, -4.2378], [ 1.3662, 6.2816], [ 4.8566, -2.797 ], [ 2.4947, 3.5425], [ 2.6414, 3.4424], [ 3.0274, -1.8749], [ 1.8957, 4.1716], [ 0.3048, 2.5195], [-0.8176, 1.9724], [ 2.2711, -1.0521], [-1.4846, 6.1564], [ 1.5305, 2.4364], [-3.6281, 4.7268], [ 1.9209, 3.1358], [-0.1875, 1.3458], [ 1.5508, 1.1897], [-0.453 , 3.157 ], [ 0.3166, 5.6812], [ 1.2475, -1.2925], [ 0.6289, -0.0265], [ 4.5071, -3.9719], [-4.6409, 7.5164], [ 0.6281, 2.217 ], [ 3.914 , -1.1867], [-1.4267, 5.0641], [-0.6267, 0.6514], [ 0.2353, 1.9975], [-0.5444, 4.3321], [ 0.2872, 1.536 ], [ 1.525 , 2.8937], [ 3.0588, -2.5527], [ 0.4209, 3.2408], [ 0.7062, 1.4383], [ 2.6603, -2.1632], [ 1.8192, -4.1824], [-0.0446, -1.9047], [-0.6859, 1.9545], [ 2.4622, 5.5611], [ 0.8626, 0.7514], [ 0.1203, 0.3933], [ 3.4888, -0.1091], [-0.044 , 5.6352], [ 0.1169, 7.151 ], [ 2.8861, 0.7694], [ 1.8575, 1.6054], [ 1.0553, 0.9859], [-1.6186, 5.4372], [ 0.1434, 2.5842], [-2.7287, 3.4333], [ 1.2537, 3.4039], [ 3.8895, 0.3228], [ 2.703 , 2.7327], [ 2.1067, -0.8624], [ 2.1412, -2.6187], [ 0.4335, 1.0761], [ 2.4168, 0.7427], [ 1.2818, 2.3239], [ 0.9299, -0.7568], [ 2.7285, 4.723 ], [ 2.0622, -1.2527], [ 0.6134, -1.1116], [ 0.1832, 1.8245], [ 0.6402, 3.063 ], [ 0.0104, 0.6147], [-0.1717, 2.4591], [ 3.1577, 0.0922], [-0.5113, 1.2958], [-1.087 , 2.3454], [ 5.1135, 1.6048], [ 1.1075, 3.9919], [ 3.1513, 6.5368]])
</div>
</div>
</div>
<div markdown="1" class="cell code_cell">
<div class="input_area" markdown="1">
```np.set_printoptions(4, suppress=True) # show only four decimals
print (X[:10,:]) # print the first 10 rows of X (from 0 to 9)
We round the whole data for only 4 decimals.
However, there is no obvious relationship based on this 2-dimensional data, hence we plot it.
plt.scatter(X[:,0], X[:,1], c= "b", edgecolor = "black")
plt.axis('equal') # equal scaling on both axis;
We can have a look at the actual covariance matrix,as well:
```print (np.cov(X,rowvar=False))
</div>
<div class="output_wrapper" markdown="1">
<div class="output_subarea" markdown="1">
{:.output_stream}
[[ 3.0298 -2.0123] [-2.0123 6.9672]]
</div>
</div>
</div>
# Running PCA
- - -- - -- - -
We would now like to analyze the directions in which the data varies most. For that, we
1. place the point cloud in the center (0,0) and
2. rotate it, such that the direction with most variance is parallel to the x-axis.
Both steps can be done using PCA, which is conveniently available in sklearn.
We start by loading the PCA class from the sklearn package and creating an instance of the class:
<div markdown="1" class="cell code_cell">
<div class="input_area" markdown="1">
```from sklearn.decomposition import PCA
pca = PCA()
Now, pca is an object which has a function pca.fit_transform(x) which performs both steps from above to its argument x, and returns the centered and rotated version of x.
```X_pca = pca.fit_transform(X)
</div>
</div>
<div markdown="1" class="cell code_cell">
<div class="input_area" markdown="1">
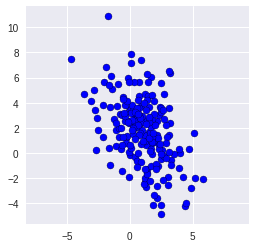
```pca.components_
plt.scatter(X_pca[:,0], X_pca[:,1],c = "b", edgecolor = "black")
plt.axis('equal');
The covariances between different axes should be zero now. We can double-check by having a look at the non-diagonal entries of the covariance matrix:
```print (np.cov(X_pca, rowvar=False))
</div>
<div class="output_wrapper" markdown="1">
<div class="output_subarea" markdown="1">
{:.output_stream}
[[7.8137 0. ] [0. 2.1833]]
</div>
</div>
</div>
High-Dimensional Data
=====================
Our small example above was very easy, since we could get insight into the data by simply plotting it. This approach will not work once you have more than 3 dimensions, Let's use the famous iris dataset, which has the following 4 dimensions:
* Sepal Length
* Sepal Width
* Pedal Length
* Pedal Width
<div markdown="1" class="cell code_cell">
<div class="input_area" markdown="1">
```!wget https://raw.githubusercontent.com/RPI-DATA/tutorials-intro/master/principal-components-clustering/notebooks/bezdekIris.data
```from io import open data = open(‘bezdekIris.data’, ‘r’).readlines() iris_HD = np.matrix([np.array(val.split(‘,’)[:4]).astype(float) for val in data[:-1]])
</div>
</div>
Lets look at the data again. First, the raw data:
<div markdown="1" class="cell code_cell">
<div class="input_area" markdown="1">
```print (iris_HD[:10])
Since each dimension has different scale in the Iris Database, we can use StandardScaler to standard the unit of all dimension onto unit scale.
```from sklearn.preprocessing import StandardScaler iris_HD = StandardScaler().fit_transform(iris_HD) iris_HD
</div>
<div class="output_wrapper" markdown="1">
<div class="output_subarea" markdown="1">
{:.output_data_text}
array([[-0.9007, 1.019 , -1.3402, -1.3154], [-1.143 , -0.132 , -1.3402, -1.3154], [-1.3854, 0.3284, -1.3971, -1.3154], [-1.5065, 0.0982, -1.2834, -1.3154], [-1.0218, 1.2492, -1.3402, -1.3154], [-0.5372, 1.9398, -1.1697, -1.0522], [-1.5065, 0.7888, -1.3402, -1.1838], [-1.0218, 0.7888, -1.2834, -1.3154], [-1.7489, -0.3622, -1.3402, -1.3154], [-1.143 , 0.0982, -1.2834, -1.4471], [-0.5372, 1.4794, -1.2834, -1.3154], [-1.2642, 0.7888, -1.2266, -1.3154], [-1.2642, -0.132 , -1.3402, -1.4471], [-1.87 , -0.132 , -1.5107, -1.4471], [-0.0525, 2.17 , -1.4539, -1.3154], [-0.1737, 3.0908, -1.2834, -1.0522], [-0.5372, 1.9398, -1.3971, -1.0522], [-0.9007, 1.019 , -1.3402, -1.1838], [-0.1737, 1.7096, -1.1697, -1.1838], [-0.9007, 1.7096, -1.2834, -1.1838], [-0.5372, 0.7888, -1.1697, -1.3154], [-0.9007, 1.4794, -1.2834, -1.0522], [-1.5065, 1.2492, -1.5676, -1.3154], [-0.9007, 0.5586, -1.1697, -0.9205], [-1.2642, 0.7888, -1.056 , -1.3154], [-1.0218, -0.132 , -1.2266, -1.3154], [-1.0218, 0.7888, -1.2266, -1.0522], [-0.7795, 1.019 , -1.2834, -1.3154], [-0.7795, 0.7888, -1.3402, -1.3154], [-1.3854, 0.3284, -1.2266, -1.3154], [-1.2642, 0.0982, -1.2266, -1.3154], [-0.5372, 0.7888, -1.2834, -1.0522], [-0.7795, 2.4002, -1.2834, -1.4471], [-0.416 , 2.6304, -1.3402, -1.3154], [-1.143 , 0.0982, -1.2834, -1.3154], [-1.0218, 0.3284, -1.4539, -1.3154], [-0.416 , 1.019 , -1.3971, -1.3154], [-1.143 , 1.2492, -1.3402, -1.4471], [-1.7489, -0.132 , -1.3971, -1.3154], [-0.9007, 0.7888, -1.2834, -1.3154], [-1.0218, 1.019 , -1.3971, -1.1838], [-1.6277, -1.7434, -1.3971, -1.1838], [-1.7489, 0.3284, -1.3971, -1.3154], [-1.0218, 1.019 , -1.2266, -0.7889], [-0.9007, 1.7096, -1.056 , -1.0522], [-1.2642, -0.132 , -1.3402, -1.1838], [-0.9007, 1.7096, -1.2266, -1.3154], [-1.5065, 0.3284, -1.3402, -1.3154], [-0.6583, 1.4794, -1.2834, -1.3154], [-1.0218, 0.5586, -1.3402, -1.3154], [ 1.4015, 0.3284, 0.5354, 0.2641], [ 0.6745, 0.3284, 0.4217, 0.3958], [ 1.2803, 0.0982, 0.6491, 0.3958], [-0.416 , -1.7434, 0.1375, 0.1325], [ 0.7957, -0.5924, 0.4786, 0.3958], [-0.1737, -0.5924, 0.4217, 0.1325], [ 0.5533, 0.5586, 0.5354, 0.5274], [-1.143 , -1.5132, -0.2603, -0.2624], [ 0.9168, -0.3622, 0.4786, 0.1325], [-0.7795, -0.8226, 0.0807, 0.2641], [-1.0218, -2.4339, -0.1466, -0.2624], [ 0.0687, -0.132 , 0.2512, 0.3958], [ 0.1898, -1.9736, 0.1375, -0.2624], [ 0.311 , -0.3622, 0.5354, 0.2641], [-0.2948, -0.3622, -0.0898, 0.1325], [ 1.038 , 0.0982, 0.3649, 0.2641], [-0.2948, -0.132 , 0.4217, 0.3958], [-0.0525, -0.8226, 0.1944, -0.2624], [ 0.4322, -1.9736, 0.4217, 0.3958], [-0.2948, -1.283 , 0.0807, -0.1308], [ 0.0687, 0.3284, 0.5922, 0.7907], [ 0.311 , -0.5924, 0.1375, 0.1325], [ 0.5533, -1.283 , 0.6491, 0.3958], [ 0.311 , -0.5924, 0.5354, 0.0009], [ 0.6745, -0.3622, 0.3081, 0.1325], [ 0.9168, -0.132 , 0.3649, 0.2641], [ 1.1592, -0.5924, 0.5922, 0.2641], [ 1.038 , -0.132 , 0.7059, 0.659 ], [ 0.1898, -0.3622, 0.4217, 0.3958], [-0.1737, -1.0528, -0.1466, -0.2624], [-0.416 , -1.5132, 0.0239, -0.1308], [-0.416 , -1.5132, -0.033 , -0.2624], [-0.0525, -0.8226, 0.0807, 0.0009], [ 0.1898, -0.8226, 0.7628, 0.5274], [-0.5372, -0.132 , 0.4217, 0.3958], [ 0.1898, 0.7888, 0.4217, 0.5274], [ 1.038 , 0.0982, 0.5354, 0.3958], [ 0.5533, -1.7434, 0.3649, 0.1325], [-0.2948, -0.132 , 0.1944, 0.1325], [-0.416 , -1.283 , 0.1375, 0.1325], [-0.416 , -1.0528, 0.3649, 0.0009], [ 0.311 , -0.132 , 0.4786, 0.2641], [-0.0525, -1.0528, 0.1375, 0.0009], [-1.0218, -1.7434, -0.2603, -0.2624], [-0.2948, -0.8226, 0.2512, 0.1325], [-0.1737, -0.132 , 0.2512, 0.0009], [-0.1737, -0.3622, 0.2512, 0.1325], [ 0.4322, -0.3622, 0.3081, 0.1325], [-0.9007, -1.283 , -0.4308, -0.1308], [-0.1737, -0.5924, 0.1944, 0.1325], [ 0.5533, 0.5586, 1.2743, 1.7121], [-0.0525, -0.8226, 0.7628, 0.9223], [ 1.5227, -0.132 , 1.2175, 1.1856], [ 0.5533, -0.3622, 1.0469, 0.7907], [ 0.7957, -0.132 , 1.1606, 1.3172], [ 2.1285, -0.132 , 1.6153, 1.1856], [-1.143 , -1.283 , 0.4217, 0.659 ], [ 1.765 , -0.3622, 1.4448, 0.7907], [ 1.038 , -1.283 , 1.1606, 0.7907], [ 1.6438, 1.2492, 1.3311, 1.7121], [ 0.7957, 0.3284, 0.7628, 1.0539], [ 0.6745, -0.8226, 0.8764, 0.9223], [ 1.1592, -0.132 , 0.9901, 1.1856], [-0.1737, -1.283 , 0.7059, 1.0539], [-0.0525, -0.5924, 0.7628, 1.5805], [ 0.6745, 0.3284, 0.8764, 1.4488], [ 0.7957, -0.132 , 0.9901, 0.7907], [ 2.2497, 1.7096, 1.6722, 1.3172], [ 2.2497, -1.0528, 1.7858, 1.4488], [ 0.1898, -1.9736, 0.7059, 0.3958], [ 1.2803, 0.3284, 1.1038, 1.4488], [-0.2948, -0.5924, 0.6491, 1.0539], [ 2.2497, -0.5924, 1.6722, 1.0539], [ 0.5533, -0.8226, 0.6491, 0.7907], [ 1.038 , 0.5586, 1.1038, 1.1856], [ 1.6438, 0.3284, 1.2743, 0.7907], [ 0.4322, -0.5924, 0.5922, 0.7907], [ 0.311 , -0.132 , 0.6491, 0.7907], [ 0.6745, -0.5924, 1.0469, 1.1856], [ 1.6438, -0.132 , 1.1606, 0.5274], [ 1.8862, -0.5924, 1.3311, 0.9223], [ 2.492 , 1.7096, 1.5016, 1.0539], [ 0.6745, -0.5924, 1.0469, 1.3172], [ 0.5533, -0.5924, 0.7628, 0.3958], [ 0.311 , -1.0528, 1.0469, 0.2641], [ 2.2497, -0.132 , 1.3311, 1.4488], [ 0.5533, 0.7888, 1.0469, 1.5805], [ 0.6745, 0.0982, 0.9901, 0.7907], [ 0.1898, -0.132 , 0.5922, 0.7907], [ 1.2803, 0.0982, 0.9333, 1.1856], [ 1.038 , 0.0982, 1.0469, 1.5805], [ 1.2803, 0.0982, 0.7628, 1.4488], [-0.0525, -0.8226, 0.7628, 0.9223], [ 1.1592, 0.3284, 1.2175, 1.4488], [ 1.038 , 0.5586, 1.1038, 1.7121], [ 1.038 , -0.132 , 0.8196, 1.4488], [ 0.5533, -1.283 , 0.7059, 0.9223], [ 0.7957, -0.132 , 0.8196, 1.0539], [ 0.4322, 0.7888, 0.9333, 1.4488], [ 0.0687, -0.132 , 0.7628, 0.7907]])
</div>
</div>
</div>
We can also try plot a few two-dimensional projections, with combinations of 2 features at a time:
<div markdown="1" class="cell code_cell">
<div class="input_area" markdown="1">
```colorClass = [val.split(',')[-1].replace('\n', '') for val in data[:-1]]
for i in range(len(colorClass)):
val = colorClass[i]
if val == 'Iris-setosa':
colorClass[i] ='r'
elif val == 'Iris-versicolor':
colorClass[i] ='b'
elif val == 'Iris-virginica':
colorClass[i] ='g'
plt.figure(figsize=(8,8))
for i in range(0,4):
for j in range(0,4):
plt.subplot(4, 4, i * 4 + j + 1)
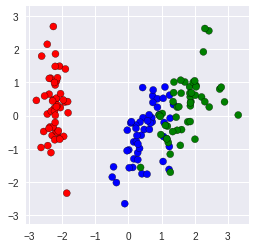
plt.scatter(iris_HD[:,i].tolist(), iris_HD[:,j].tolist(),c = colorClass, edgecolors = "black")
plt.axis('equal')
plt.gca().set_aspect('equal')
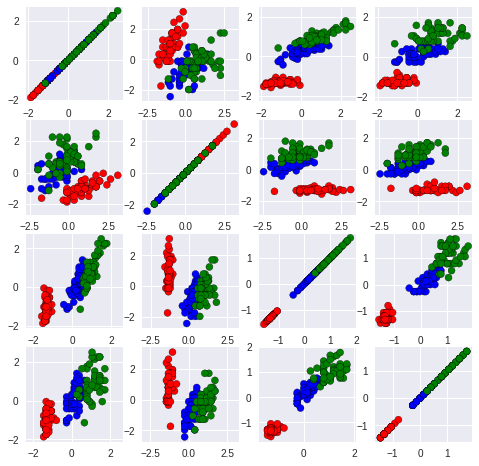
It is not easy to see that this is still a two-dimensional dataset!
However, if we now do PCA on it, you’ll see that the last two dimensions do not matter at all:
```pca = PCA() X_HE = pca.fit_transform(iris_HD) print (X_HE[:10,:])
</div>
<div class="output_wrapper" markdown="1">
<div class="output_subarea" markdown="1">
{:.output_stream}
[[-2.2647 0.48 -0.1277 -0.0242] [-2.081 -0.6741 -0.2346 -0.103 ] [-2.3642 -0.3419 0.0442 -0.0284] [-2.2994 -0.5974 0.0913 0.066 ] [-2.3898 0.6468 0.0157 0.0359] [-2.0756 1.4892 0.027 -0.0066] [-2.444 0.0476 0.3355 0.0368] [-2.2328 0.2231 -0.0887 0.0246] [-2.3346 -1.1153 0.1451 0.0269] [-2.1843 -0.469 -0.2538 0.0399]]
</div>
</div>
</div>
By looking at the data after PCA, it is easy to see the value of last two dimension, especially the last one, is pretty small such that the data can be considered as **still only two-dimensional**. To prove this we can use the code `PCA(0.95)` to told PCA choose the least number of PCA components such that 95% of the data can be kept.
Lets give a try on it!
<div markdown="1" class="cell code_cell">
<div class="input_area" markdown="1">
```pca = PCA(0.95)
X_95 = pca.fit_transform(iris_HD)
print (X_95[:10,:])
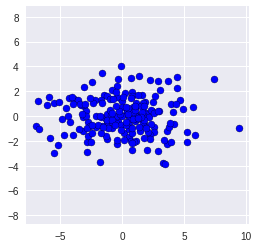
We can see that PCA eliminate ** the last two dimension** cause they are redundant under our requirment. Let’s plot the two dimension
plt.scatter(X_HE[:,0], X_HE[:,1], c = colorClass, edgecolor = "black")
plt.axis('equal')
plt.gca().set_aspect('equal')
We can have a look on the relationship between each dimention from following plots.
for i in range(4):
for j in range(4):
plt.subplot(4, 4, i * 4 + j + 1)
plt.scatter(X_HE[:,i], X_HE[:,j], c = colorClass, edgecolor = "black")
plt.gca().set_xlim(-40,40)
plt.gca().set_ylim(-40,40)
plt.axis('equal')
plt.gca().set_aspect('equal')
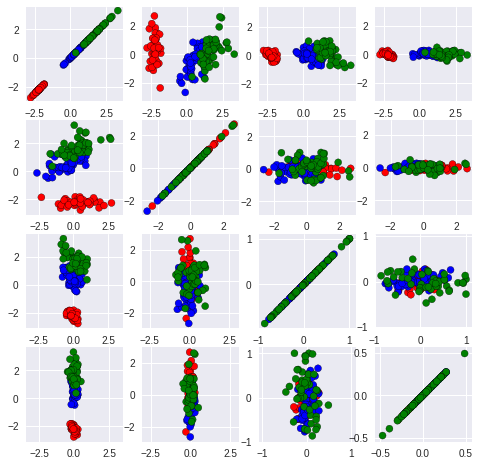
It is easy to see that the correlation between other dimensions (other than first two) was ambiguous and highly concentrated in either horizontal or vertical line. This fact suggests that there are large difference between the dimension we select so that the weak dimension cant change too much on the shape of graph.
Dimension Reduction with PCA
We can see that there are actually only two dimensions in the dataset.
Let’s throw away even more data – the second dimension – and reconstruct the original data in D.
```pca = PCA(1) # only keep one dimension! X_E = pca.fit_transform(iris_HD) print (X_E[:10,:])
</div>
<div class="output_wrapper" markdown="1">
<div class="output_subarea" markdown="1">
{:.output_stream}
[[-2.2647] [-2.081 ] [-2.3642] [-2.2994] [-2.3898] [-2.0756] [-2.444 ] [-2.2328] [-2.3346] [-2.1843]]
</div>
</div>
</div>
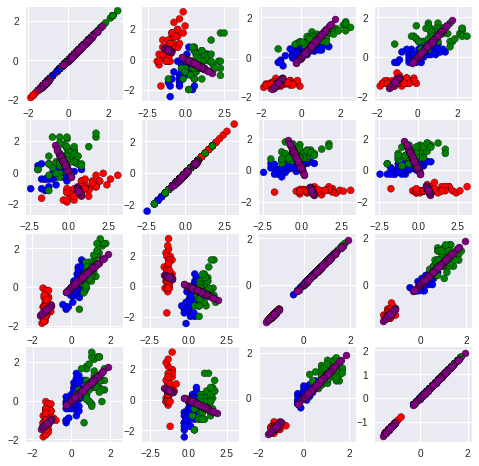
Now lets plot the reconstructed data and compare to the original data D. We plot the original data in red, and the reconstruction with only one dimension in blue:
<div markdown="1" class="cell code_cell">
<div class="input_area" markdown="1">
```X_reconstructed = pca.inverse_transform(X_E)
plt.figure(figsize=(8,8))
for i in range(4):
for j in range(4):
plt.subplot(4, 4, i * 4 + j + 1)
plt.scatter(iris_HD[:,i].tolist(), iris_HD[:,j].tolist(),c=colorClass, edgecolor = "black")
plt.scatter(X_reconstructed[:,i], X_reconstructed[:,j],c='purple', edgecolor = "black")
plt.axis('equal')
Homework
1) Do the PCA reduction on the ramdon 6-dimension data and plot it out.
2) Explan what PCA does on your data.
*The code for data are given.
DATA = np.dot(X,np.random.uniform(0.2,3,(2,6))*(np.random.randint(0,2,(2,6))*2-1))
DATA
```## Answer:
pca=PCA(6) DATA = np.dot(X,np.random.uniform(0.2,3,(2,6))(np.random.randint(0,2,(2,6))2-1)) DATA2 = pca.fit_transform(DATA)
plt.figure(figsize=(4,4)) plt.scatter(DATA2[:,0], DATA2[:,1], c = “b”, edgecolor = “black”) plt.axis(‘equal’) plt.gca().set_aspect(‘equal’)
```